
Hi Masamitsu, I'm afraid I do not have a good idea about how to do this. Indeed with a regexp expression you can select the entire text: (1), (2), and (3)terminal but I have no solution for the situation in which you want the Find Next to find sequentially (1), (2) and (3). Regards, Radu Radu Coravu Oxygen XML Editor On 1/28/21 05:39, 一木 雅光 wrote:
Dear Radu Coravu,
I do apologize for my unclear explanation. Naoki Hirai has corrected my regular expressions, but reached a conclusion that what I wanted to find was not realistic.
But if you have any idea, please let me know.
*Corrected regular expression: * \([\d|a-z|A-Z]+?\)|\)[\d|a-z|A-Z]
*What I wanted to find: * Example sentence: (1), (2), and (3)terminal Find "(1)" "(2)" "(3)" and ")t" everytime pressing [next].
Thank you. Regards, Masamitsu Ichiki
■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ クボタエイトサービス株式会社 オフィス情報サービス本部 堺CAEセンター 一木 雅光 masamitsu.ichiki@kubota.com <mailto:masamitsu.ichiki@kubota.com> 〒590-0806 大阪府堺市堺区緑ヶ丘北町1-1-36 クボタサービスセンター ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■
2021年1月28日(木) 9:24 一木 雅光 <masamitsu.ichiki@kubota.com <mailto:masamitsu.ichiki@kubota.com>>:
Dear Radu Coravu,
Thank you so much for helping us all the time.
Today, I am writing an email to ask you for any solutions regarding Find/Replace.
Question: If I would like to find these sets at a time (not separately), how will the search settings be?
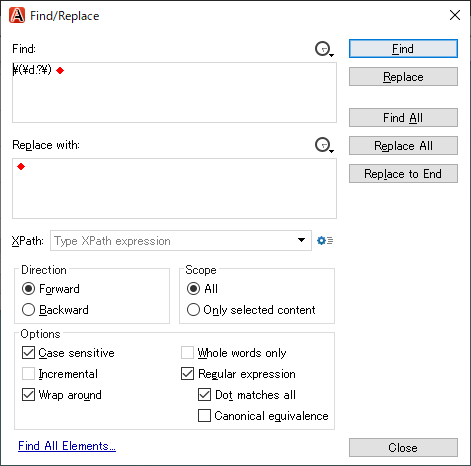
* Numbers with brackets on both sides, such as (1), (2)... (99) image.png By using "\(\d.?\)", I could highlight what I wanted.
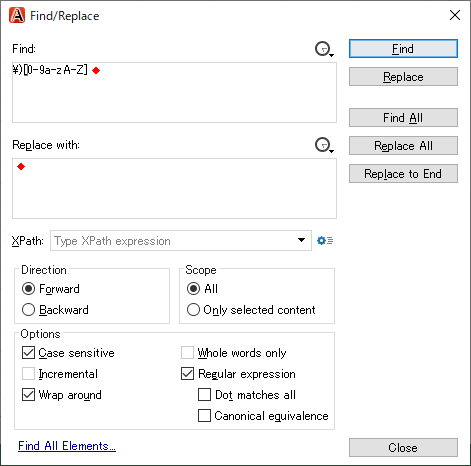
* No spacing after ")", such as "(3)terminal" image.png By using "\)[0-9a-zA-Z]", I could highlight what I wanted.
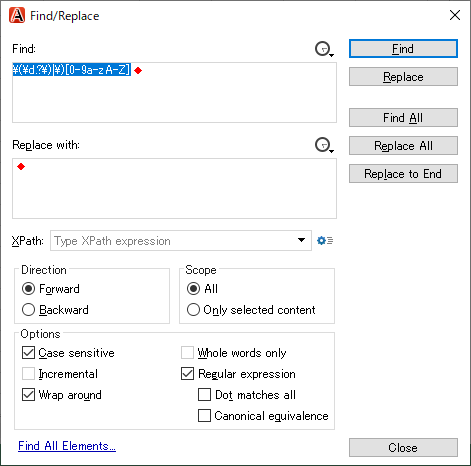
* Numbers with brackets and missing a space after closing brackets, such as "(1), (2) and (3)terminal" image.png (1), (2) and (3) are highlighted but not ")t".
Thank you for helping us and we await your response.
Yours sincerely, Masamitsu Ichiki
■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ クボタエイトサービス株式会社 オフィス情報サービス本部 堺CAEセンター 一木 雅光 masamitsu.ichiki@kubota.com <mailto:masamitsu.ichiki@kubota.com> 〒590-0806 大阪府堺市堺区緑ヶ丘北町1-1-36 クボタサービスセンター ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■
2020年11月17日(火) 16:13 一木 雅光 <masamitsu.ichiki@kubota.com <mailto:masamitsu.ichiki@kubota.com>>:
Dear Radu Coravu,
Thank you so much for your reply. Your clear explanation helped me understand how it works and what to do to find things or letters at the beginning and the end of block elements (same as external tags?).
image.png
Once again, thank you for your help.
Regards, Masamitsu Ichiki
■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ クボタエイトサービス株式会社 オフィス情報サービス本部 堺CAEセンター 一木 雅光 masamitsu.ichiki@kubota.com <mailto:masamitsu.ichiki@kubota.com> 〒590-0806 大阪府堺市堺区緑ヶ丘北町1-1-36 クボタサービスセンター ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■
2020年11月17日(火) 14:34 Radu Coravu <support@oxygenxml.com <mailto:support@oxygenxml.com>>:
Dear Masamitsu Ichiki,
Thank you for contacting us.
I searched for your initial email but could not find it in our email system, sorry about this, it probably got lost somehow. So I'm glad you wrote to us again.
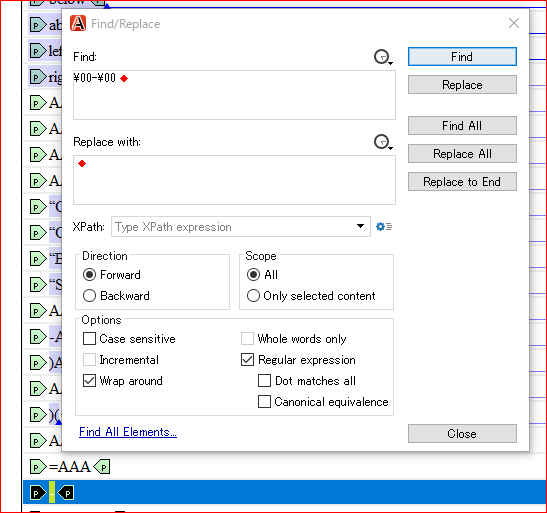
In a document opened in the Author visual editing mode there are inline elements like the DITA <b> and <i> and block elements like <p>. When you search content the inline elements are transparent and their text is considered to be part of the parent paragraph. But block elements contribute special hidden characters with the digital value "0" corresponding to their start and end.
So for what you want you can search using this regexp "\00-\00", it means find a "-" between two "0" special characters which mark a block element. You can also use the "XPath" filter with an expression like "//p" to focus only on DITA <p> elements.
I added an internal issue to see if we can make the original expression you tried "^-$" work also for such situation.
Regards,
Radu
Radu Coravu Oxygen XML Editor
On 11/17/20 6:15 AM, 一木 雅光 wrote:
Dear Sir or Madam,
My name is Masamitsu Ichiki and I am writing to you again (to a different email address) since there has been no reply from you for days.
Would you please help me find "a text which contains only '-' between a pair of <p> tags? " Please refer to my previous email for more information.
I look forward to hearing from you soon. Yours sincerely,
Masamitsu Ichiki ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ クボタエイトサービス株式会社 オフィス情報サービス本部 堺CAEセンター 一木 雅光 masamitsu.ichiki@kubota.com <mailto:masamitsu.ichiki@kubota.com> 〒590-0806 大阪府堺市堺区緑ヶ丘北町1-1-36 クボタサービスセンター ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■
2020年11月13日(金) 13:41 一木 雅光 <masamitsu.ichiki@kubota.com <mailto:masamitsu.ichiki@kubota.com>>:
Dear Sir or Madam,
My name is Masamitsu Ichiki and I am writing to you from Japan.
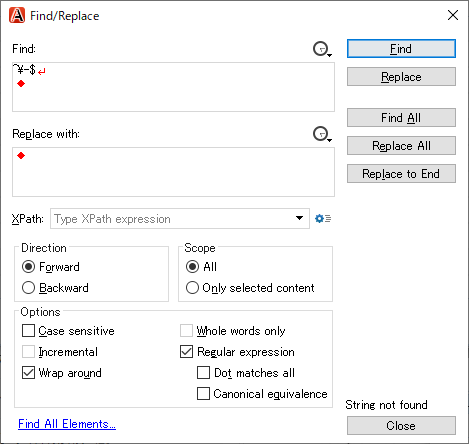
I have a question about regular expression search regarding your product, Oxygen. *How can I find a text which contains only "-" between a pair of <p> tags? * image.png
I have tried these regular expressions as follows, but none of them could hit for the search.
* ^\-$ * ^-$ * ^\- * \-$
Search settings are shown as below. image.png
As either "-" or "\-" hits the search, it seems start (^) and end ($) are not working properly.
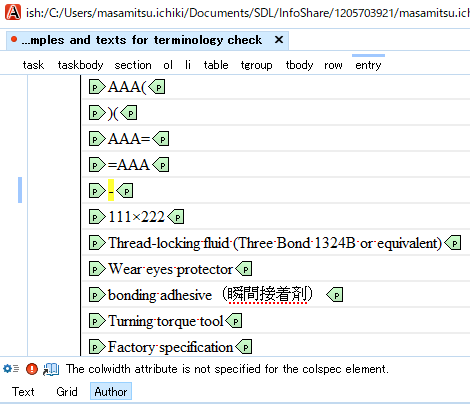
For your information, I am searching the hyphen on a Author mode, not Text mode, and I would like to know the way to find - on the Author mode. image.png
I look forward to hearing from you soon. Yours sincerely,
Masamitsu Ichiki ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ クボタエイトサービス株式会社 オフィス情報サービス本部 堺CAEセンター 一木 雅光 masamitsu.ichiki@kubota.com <mailto:masamitsu.ichiki@kubota.com> 〒590-0806 大阪府堺市堺区緑ヶ丘北町1-1-36 クボタサービスセンター ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■ □ ■
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}